
")
")
Результаты за 2013 год
Разработана архитектура вычислительного высокопроизводительного конвейера для решения задачи моделирования распространения волн цунами на базе спецвычислителей, имеющих в своем составе FPGA в качестве процессорного устройства и динамическую память.
Область применения: в области математического моделирования числовых и разностных схем с целью наблюдения и прогнозирования природных явлений.
Для моделирования распространения волны цунами применялась линейная система уравнений мелкой воды в виде, используемом мировыми центрами предупреждения (такая гиперболическая система, предложенная В.А. Титовым, допускает симметризацию с последующим использованием метода расщепления). В работе рассмотрен вариант решения задачи моделирования цунами с использованием FPGA и предложен масштабируемый вычислительный конвейер для FPGA семейств Virtex-5, Virtex-6 и Virtex/Kintex-7 на языке описания аппаратуры VHDL.
Предложенный вычислительный конвейер был реализован на базе двух спецвычислителей:
- на базе спецвычислителя FD842 (FPGA Xilinx xc5vlx30t). Было выяснено, что вычислитель может работать на частоте 62.5 МГц. На реализацию предложенного базового конвейера было затрачено более 90% объема кристалла, что не позволило использовать внешнюю динамическую память. В ходе тестирования было выяснено, что предложенный метод взаимодействия без DRAM (последовательная постраничная запись в FPGA) не дает ожидаемого эффекта (по сравнению с использованием графических ускорителей) из-за накладных расходов на обработку прерываний в драйвере (85% времени вычислитель простаивает в ожидании данных от ПК).
- на базе спецвычислителя SLEDv7 (FPGA Xilinx xc6vsx315t). Данный спецвычислитель имеет 2 независимых контроллера внешней динамической памяти DDR3. Емкость кристалла позволила реализовать вычислительный конвейер с коэффициентом масштабирования 10, а также использовать имеющуюся на борту внешнюю память для хранения исходных данных и промежуточных результатов. В данный момент происходит отладка программного обеспечения для запуска серии реальных тестов, но по результатам моделирования, итоговое увеличение производительности составит порядка 100 раз по сравнению с реализацией на базе спецвычислителя FD842.
В ходе работы был создан вычислительный конвейер для решения задачи моделирования распространения волны цунами. Данный конвейер разработан таким образом, что его можно легко масштабировать под используемый спецвычислитель, исходя из исполдьзуемого кристалла FPGA, а также наличия и количества внешней памяти. Также были разработаны принципы проектирования аппаратных спецвычислителей на базе FPGA для решения задач математического моделирования, особенностью которых являются многопроходность и использование большого количества начальных и промежуточных данных.
В настоящий момент в лаборатории закончена разработка нового аппаратного решения SLEDv7 на базе кристалла xc6vsx315t. Данный аппаратный комплекс обладает большим объемом логических элементов и содержит в себе большое количество блоков DSP, что позволяет сократить затраты на логические элементы. Помимо этого, использование таких блоков позволяет повысить тактовую частоту вычислителя и, соответственно, производительность. По результатам моделирования, использование предложенного аппаратного комплекса позволяет увеличить конвейер в 10 раз. С учетом пропускной способности интерфейсов памяти DDR3, установленной на данной плате итоговое увеличение производительности по сравнению с реализацией на аппаратном решении FD842 составляет порядка 100 раз.
В ходе выполнения работы была подготовлена и опубликована статья "FPGA Based Hardware Accelerator for High Performance Data-Stream Processing" (Pattern Recognition and Image Analysis, 2013, Vol. 23, No. 1, pp. 26–34).
По результатам программного моделирования и практического тестирования на двух программно-аппаратных комплексах были выявлены основные особенности, которые необходимо учитывать при выборе аппаратной платформы для математического моделирования подобных задач:
- Необходимо наличие внешней динамической памяти, соединенной непосредственно с вычислителем FPGA.
- Наличие двух независимых банков памяти позволяет существенно увеличить производительность вычислительного конвейера за счет распараллеливания независимых этапов вычислений.
- Объем установленной динамической памяти менее чем 4 ГБ может быть недостаточен для хранения исходных и промежуточных данных моделирования.
- Логический объем вычислителя FPGA должен быть не менее чем FPGA xc5vlx50t.
- Программная реализация драйвера аппаратного комплекса должна учитывать необходимость обработки большого количества прерываний (не менее 100 Гц) и своевременного обеспечения данными вычислительного комплекса.
Результаты за 2012 год
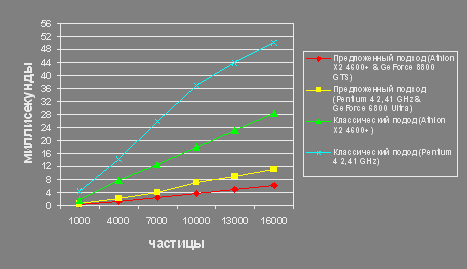
Предложены новые методы реализации системы частиц на стандартных графических акселераторах, обеспечивающие оптимальное соотношение между скоростью обработки частиц и качеством визуализации спецэффектов. Для обеспечения быстродействия предложен метод распределенной обработки анимационных составляющих спецэффекта. Обработка параметров анимации частиц осуществляется на пиксельном конвейере графического акселератора, а параметров анимации формы – на вершинном конвейере видеокарты. Разработаны алгоритмы и программное обеспечение для реализации предложенных методов на стандартных графических акселераторах.



Применение графического акселератора в качестве математического сопроцессора обеспечило пятикратное увеличение производительности по сравнению с классической реализацией.
Разработаны имитационная модель и программно-алгоритмические средства для моделирования поведения плотных автомобильных потоков на сети дорог. Модель обеспечивает реалистичное динамическое распределение автомобилей в пределах видимости наблюдателя, стабильность, предсказуемость и управляемость в широком диапазоне параметров.

Разработана интеллектуальная система управления виртуальным автомобилем в плотном дорожном трафике. Управление реализовано в виде набора допустимых маневров, применяемых в зависимости от текущей дорожной обстановки. Для каждого из автомобилей на каждом кадре принимается решение о продолжении выполнения текущего маневра или перехода на выполнение другого маневра. Разработаны и реализованы алгоритмы, представляющие следующие манёвры: движение по заданному на графе маршруту, смена полосы, обгон, остановка, проезд ответвления, проезд перекрёстка (регулируемого и нерегулируемого), объезд препятствия (в том числе и динамического), препятствование движению другого транспортного средства (полицейский обгон и экстренное торможение). Каждый из манёвров на дороге представлен соответствующим геометрическим описанием, которое позволяет точно рассчитать поведение участвующих в нём автомобилей, что в свою очередь позволяет принять однозначно определённое решение по дальнейшему распределению маневров для каждой из машин.
Предложенные алгоритмические решения могут использоваться в автомобильных тренажерах, в системах планирования и организации дорожного движения в качестве легко конфигурируемого тестового инструмента.
Разработана архитектура платы на базе FPGA и создано устройство для ускорения решения задачи поиска олигонуклеотидного мотива (сигнала) в геномной последовательности, которая является весьма распространенной задачей в области выявления сайтов связывания транскрипционных факторов. Реализация на FPGA семейства Virtex5 позволяет значительно распараллеливать операции сравнения мотивов, а также хранить во внутренней памяти кристалла входного массива данных, что позволяет значительно уменьшить обмен данных с внешней памятью и добиться значительного роста производительности. Применение разработанного программно-аппаратного комплекса HDG позволит в 2 000 раз ускорить решение задачи по сравнению с универсальным ПК на базе процессора Core2Duo. Использование же решения на базе FPGA XC5VLX330T повысит производительность в 20 000 раз.
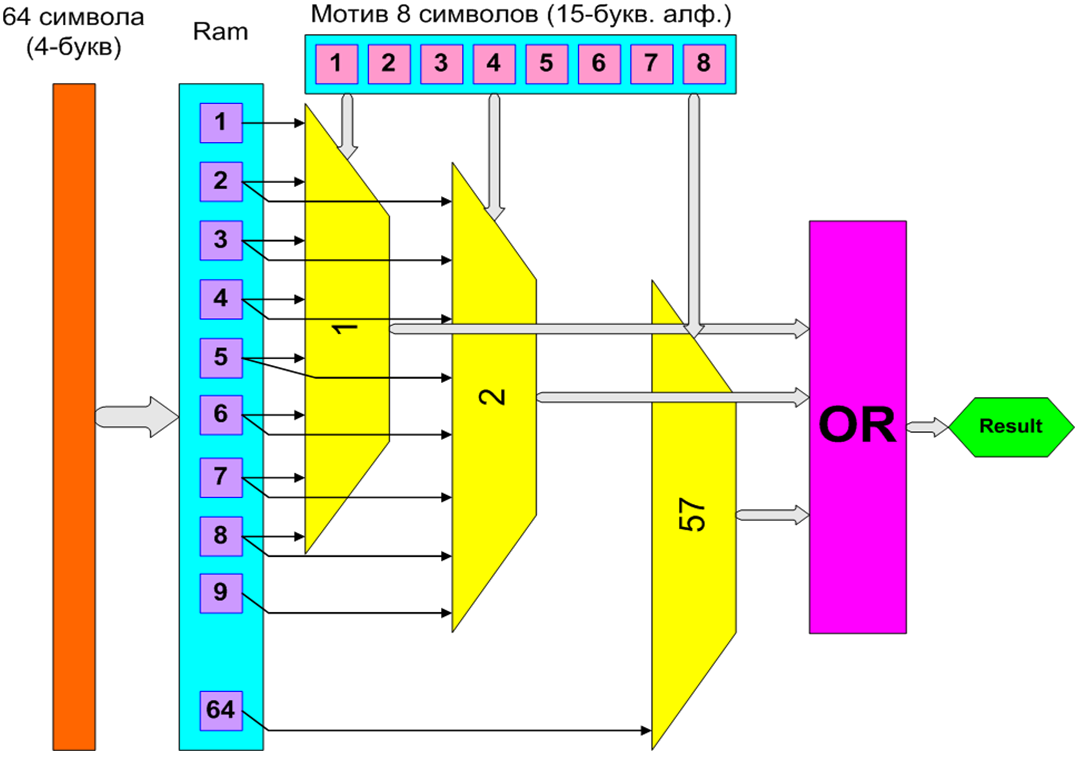
Реализация на FPGA поиска мотива в строке